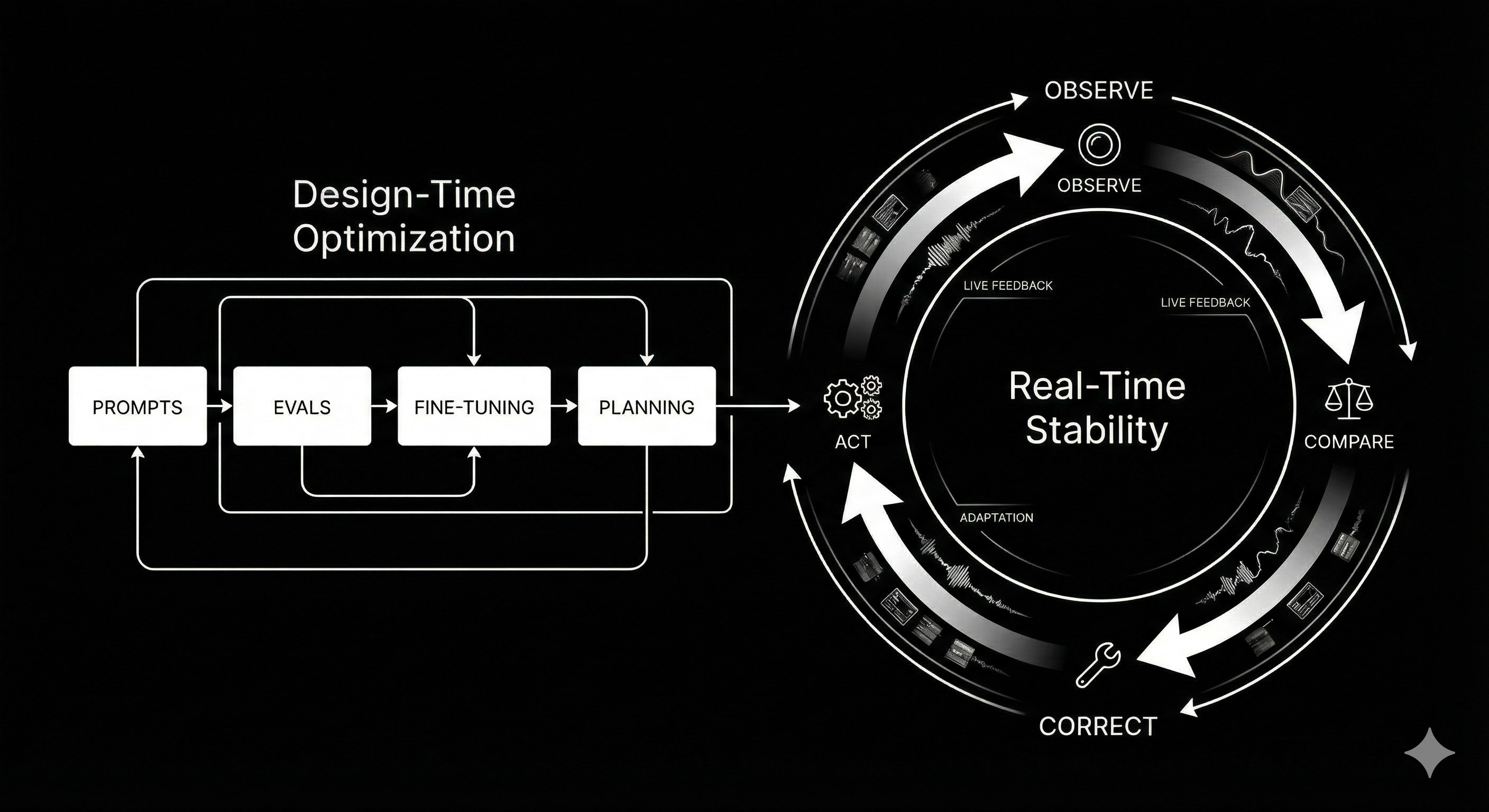
In classical control engineering, every system is shaped by two forces:
- How well it is designed before operation
- How well it stabilizes itself during operation
These are not interchangeable.
They solve fundamentally different problems.
Today's AI systems invest almost entirely in the first category — design-time optimization — while largely ignoring the second — real-time stability.
This chapter explains why that imbalance exists, how it manifests in LLM agents and browser automation, and why the future of AI requires shifting from feed-forward thinking to control-theoretic architectures.
1. The Two Forces That Shape Intelligent Systems
In manufacturing, robotics, aerospace, and even biology, the distinction is universal:
Design-time optimization
prepares the system.
Real-time stability
keeps the system alive.
Both matter.
But only one determines whether the system continues to function under uncertainty.
AI engineers are extremely good at design-time work: models, prompts, evals, fine-tuning, retrieval, and planning.
But the moment their systems touch the real world — the browser, APIs, timing, partial observability, corrupted states — everything becomes unstable.
Why?
Because design-time optimization cannot substitute for real-time control.
2. What AI Engineers Call "Performance" Is Mostly Design-Time Optimization
In LLM systems, design-time optimization includes:
- prompt engineering
- chain-of-thought templates
- RAG tuning
- dataset curation
- fine-tuning / LoRA
- planning mechanisms
- deterministic agent scripts
- evaluation-driven iteration
- tool schemas and guardrails
These techniques modify the initial feed-forward policy of the model.
They improve the start of the trajectory — not the behavior of the trajectory itself.
Example:
A browser agent's YAML spec makes it start with a better plan.
But once the DOM shifts?
Once a button moves?
Once a flow times out?
The plan becomes irrelevant.
Design-time improvements can only decrease the initial error.
They cannot correct runtime error.
This limitation is universal — you can prompt your way to a better launch, but not to a stable flight.
3. Why Real-Time Stability Is a Different Category of Intelligence
Real-time stability is not about better prompts or better models.
It's about continuous sensing, comparison, correction, and convergence.
In control engineering, this is called closed-loop control:
- Observe the world
- Compare expected vs. actual
- Compute error
- Correct immediately
- Repeat
This loop is what stabilizes:
- drones
- rockets
- autonomous vehicles
- industrial robotics
- biological systems
And, increasingly, LLM agents.
When an LLM agent interacts with the browser, the filesystem, or an API, it needs to:
- detect when it misclicked
- validate that it reached the correct state
- handle dynamic changes
- re-plan mid-run
- retry based on observed reality
- recover from drift
- correct its own hallucinations
- enforce invariants
This is online adaptation, not offline tuning.
It is what separates "smart models" from "reliable systems."
4. The Core Distinction: Preparation vs. Survival
Let's frame this concretely.
Design-time optimization
is tuning an autopilot controller before takeoff.
Real-time stability
is adjusting thrust and pitch 200 times per second as the aircraft descends through turbulence.
Both are valuable.
But they solve fundamentally different problems.
In AI terms:
- prompt engineering ≈ adjusting parameters before takeoff
- fine-tuning ≈ improving the default controller before leaving the ground
- planning ≈ optimizing the initial flight path
These all happen before the system touches uncertainty.
In contrast:
- DOM validation
- state checking
- corrective loops
- dynamic re-binding of elements
- detecting divergence
- re-planning mid-run
These happen inside uncertainty.
This is why browser automation reveals the truth faster than any other domain:
An LLM without real-time stability is a rocket without sensors.
It might launch beautifully, but it cannot land.
5. Why Fine-Tuning Feels Like Magic — But Isn't Enough
Fine-tuning looks powerful because it introduces offline feedback:
- The model sees its past failure
- It adjusts its internal policy
- It improves the first step next time
This gives the illusion of closed-loop behavior.
But it is still design-time correction, not runtime correction.
During execution:
- fine-tuning cannot detect drift
- fine-tuning cannot apply corrective action
- fine-tuning cannot recover from invalid states
- fine-tuning cannot handle timing sensitivities
- fine-tuning cannot adapt to real-world invariants
It only prepares the model.
It does not enable the model to stabilize itself.
A tuned policy is still open-loop.
Closed-loop architecture is where stability actually emerges.
6. The Control-Theoretic Reframe for AI Engineers
The key insight:
The missing piece isn't in the model.
It's in the architecture around the model.
LLMs generate intelligent actions.
Control systems ensure those actions work in the real world.
Today's systems are:
- intelligent without stability
- powerful without robustness
- capable without awareness
- high-performance without self-correction
This is why every serious agent engineering team is converging toward the same realization:
We don't need smarter models.
We need architectures that keep models stable during execution.
Closed-loop systems are the only known solution to this problem in every other field.
AI is no exception.